This post was originally made in January of 2015, but due to a take-down letter, I received a week later this story has remained unpublished for the last seven years.

Memcached was released in May of 2003 by Danga Interactive. This free, open-source software layer provides a general-purpose distributed in-memory cache that can be used by both web & app servers. Five years later, Google released version 1.1.0 of its App Engine, which also included its version of an in-memory cache called Memcache. This capability to store objects in a huge pool of memory spread across a large distributed fabric of servers is integral to the performance inherent in many of Google’s products. Google showed in a presentation earlier this year on Memcache that a query from a typical data requires 60-100 milliseconds, while a similar Memcache query only needed 3-8 milliseconds, a 20X improvement. It’s no wonder Google is a big fan of Memcache. This is why in March of 2013, Google acquired both technology and people from a small networking company called Myricom, who cracked the code to accelerate the network path to Memcache.
To better understand what Google acquired, we need to roll back to 2009 when Myricom had ported its MX communications stack to Ethernet. Mx over Ethernet (MXoE) was originally crafted for the High-Performance Computing (HPC) market, to create a very limited, but extremely low latency, stack for their then two-year-old 10GbE NICs. MXoE was reformulated using UDP instead of MX, and this new low latency driver was then named DBL. It was then engineered to service the High-Frequency Traders (HFT) on Wall Street. Throughout 2010 Myricom had evolved this stack by further adding limited TCP functionality. At that time, half round trip performance (one send plus one receive) over 10GbE was averaging 10-15 microseconds, DBL did it 4 microseconds. Today (2015) by comparison Solarflare, the leader in ultra-low latency network adapters, does this in well under 2 microseconds. So in 2012, Google was searching for a method to apply ultra-low latency networking tricks to a new technology called Memcache. In the fall of 2012 Google invited several Myricom engineers to discuss how DBL might be altered to service Memcache directly. Also they were interested in known if Myricom’s new silicon, due out in early 2013, might also be a good fit for this application. By March of 2013 Google had tendered an offer to Myricom to acquire their latest 10/40GbE chip, which was about to go into production, along with 12 of their PhDs who handled both the hardware & software architecture. Little is publicly known if that chip or the underlying accelerated driver layer for Memcache has ever made it into production at Google.
Fast forward to today (2015), and earlier this week, Solarflare released a new whitepaper highlighting how they’ve accelerated the publicly available free open-source layer called Memcached using their ultra-low latency driver layer called OpenOnload. In this whitepaper, Solarflare demonstrated performance gains of 2-3 times that of a similar Intel 10GbE adapter. Imagine Google’s Memcache farm being only 1/3 the size it is today? We’re talking serious performance gains here. For example, leveraging a 20 core server, the Intel dual 10GbE adapter supported 7.4 million multiple get operations while Solarflare provided 21.9 million, nearly a 200% increase in the number of requests. If we look at mixed throughput (get/set in a ratio of 9:1), Intel delivered 6.3 million operations per second while Solarflare delivered 13.3 million, a 110% gain. That’s throughput, how about latency performance? Using all 20 cores, and batches of 48 get requests Solarflare clocked in at 2,000 microseconds, and Intel at 6,000 microseconds. Across all latency tests, Solarflare reduced network latency by, on average, 69.4% (the lowest reduction was 50%, and the highest 85%). Here is a link to the 10-page Solarflare whitepaper with all the details.
While Google was busy acquiring technology & staff to improve their own Memcache performance, Solarflare delivered it for their customers and documented the performance gains.


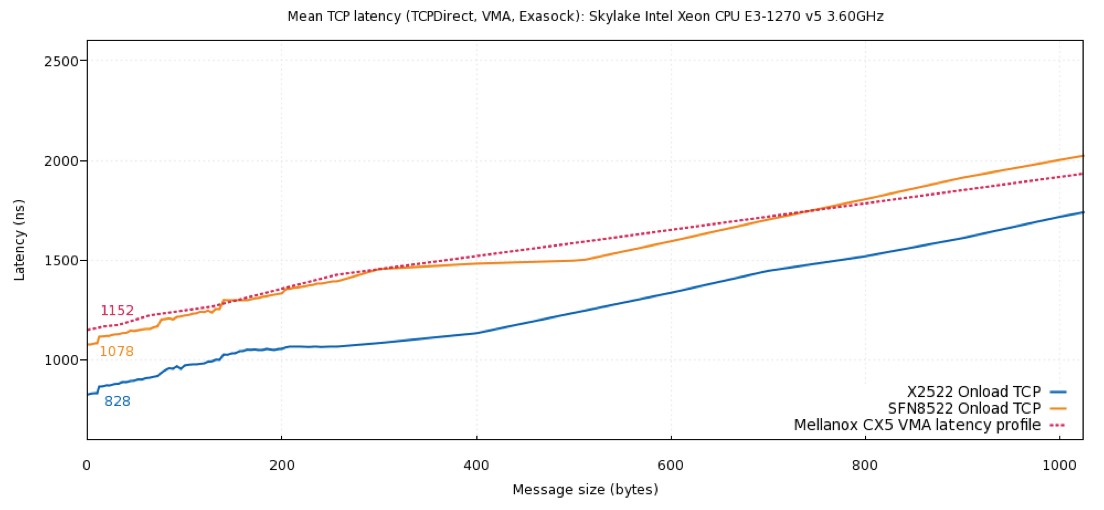





 The recently announced microprocessor architecture vulnerability known as
The recently announced microprocessor architecture vulnerability known as